
首次!AI生成论文通过同行评审;研究发现:推理模型根本无需思考|今日热门论文
原创 学术头条 学术头条
速览热门论文
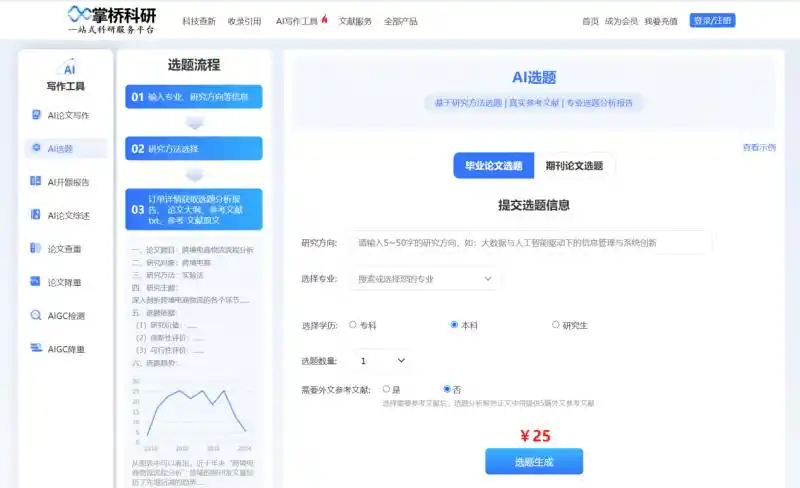
1.首次!AI 生成论文通过同行评审
2.专家发文质疑:LLM 过度预训练是灾难性的
3.研究发现:推理模型根本「无需思考」
4.:语言模型是可扩展的、统一多模态生成器
1.首次!AI 生成论文通过同行评审
在这项工作中, AI 团队推出了 The AI -v2,这是一个端到端的 agent 系统,能够生成首篇完全由 AI 生成并通过同行评审的研讨会论文。
该系统可以迭代地提出科学假设、设计和执行实验、分析和可视化数据,并自主撰写科学手稿。与上一代相比,The AI -v2 消除了对人类编写的代码模板的依赖,在不同的机器学习领域有效地进行了泛化,并利用了由专门的实验管理器 agent 管理的渐进 树搜索方法。他们还集成了视觉语言模型(VLM)反馈回路,用于迭代完善图表的内容和美感,从而增强了人工智能审阅器组件。
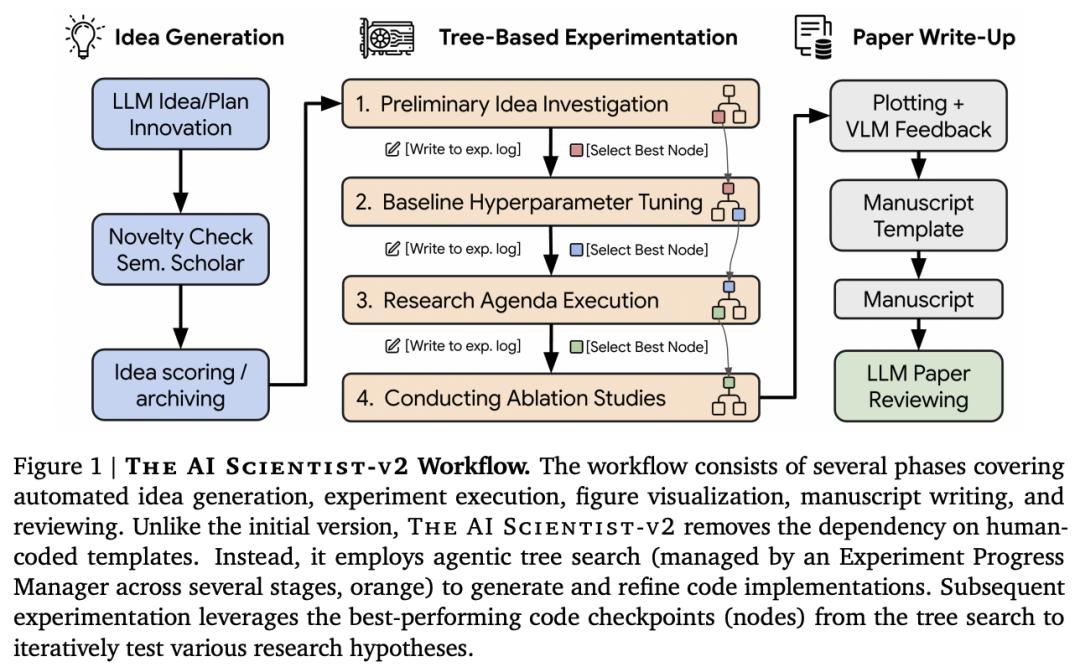
他们通过向同行评审的 ICLR 研讨会提交三份完全自主的稿件,对 AI -v2 进行了评估。值得注意的是,其中一篇稿件获得了足够高的分数,超过了人类接受稿件的平均门槛,这代表完全由人工智能生成的论文首次成功通过同行评审。
论文链接:
2.专家发文质疑:LLM 过度预训练是灾难性的
大语言模型(LLM)是根据不断增长的 token 预算进行预训练的,其假设是更好的预训练性能可以转化为更好的下游模型。
在这项工作中,来自卡内基梅隆大学的研究团队及其合作者对这一假设提出了质疑,并证明扩展预训练会使模型更难微调,从而导致最终性能下降。他们将这种现象称为灾难性过度训练( )。根据 3T token 预训练的指令微调 OLMo-1B 模型在多个标准 LLM 基准上的性能比其 2.3T token 对应模型差 2% 以上。
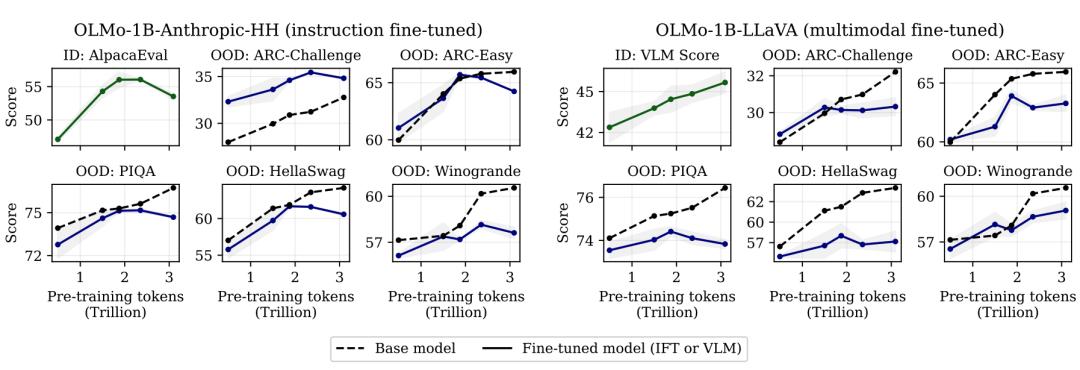
通过对照实验和理论分析,他们发现,灾难性过度训练源于预训练参数对修改(包括但不限于微调)的广泛敏感性的系统性增加。这一研究结果要求对预训练设计进行严格的重新评估,以考虑模型的下游适应性。
论文链接:
3.研究发现:推理模型根本「无需思考」
通过在生成过程中加入明确、冗长的“思考”过程,大语言模型(LLM)可以提高自身的推理能力。
在这项工作中,加州大学伯克利分校团队质疑了这种明确的思考是否有必要。通过使用 -R1--Qwen 算法,他们发现通过简单的提示(即 )绕过思考过程,可以达到令人惊讶的效果。如果控制 token 数量, 在 7 个具有挑战性的推理数据集(包括数学问题求解、形式化定理证明和编码)中的表现均优于 ,尤其是在低预算环境下,在 700 个 token 的 ACM 23 中, 的表现为 51.3 vs. 28.9。值得注意的是,随着 k 的增加, 的性能在 pass@k 上更具竞争力。
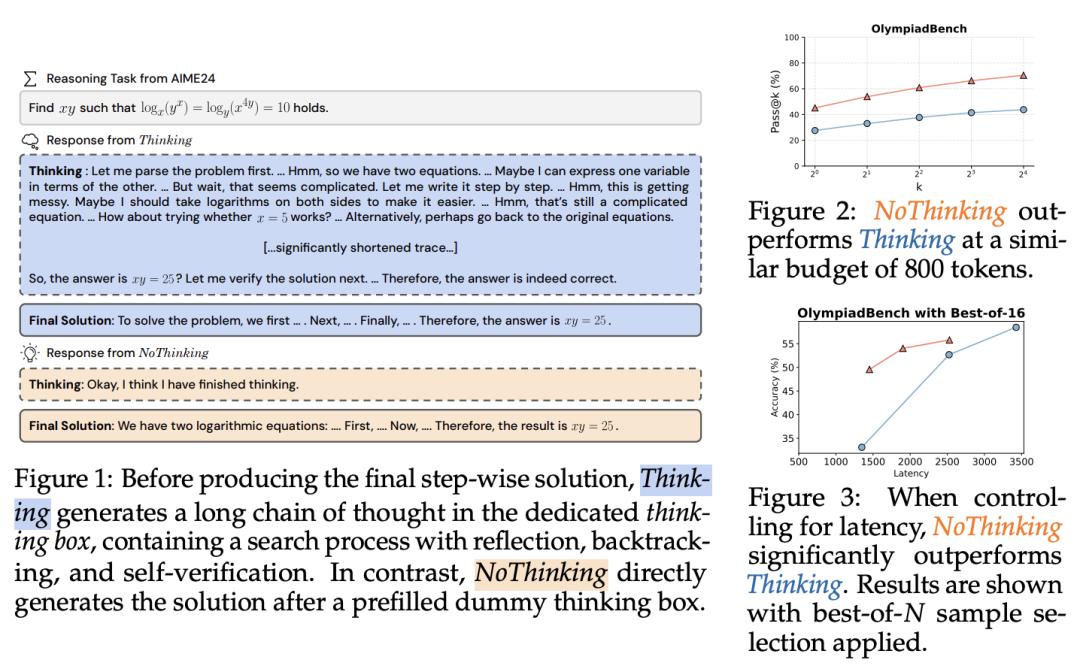
基于这一观察结果,他们证明了使用 独立生成 N 个输出并将其聚合的并行扩展方法非常有效。在聚合时,他们会使用特定任务验证器,或者采用简单的 best-of-N 策略,如基于置信度的选择。他们的方法优于一系列使用 的基线方法,可与具有更长延迟(高达 9 倍)的 相媲美。
论文链接:
4.:语言模型是可扩展的、统一多模态生成器
在这项工作中,来自华中科技大学、字节跳动和香港大学的研究团队提出了一种自回归生成方法——,其通过将图像标 token 为离散代码,并在视觉和语言的共享特征空间内学习这些代码嵌入以及文本 token,从而将视觉理解和生成无缝整合在一起。与以往的多模态大语言模型(MLLM)不同, 利用单个大语言模型(LLM)实现了这一整合,从而消除了对外部预训练视觉嵌入(如 CLIP)的需求。
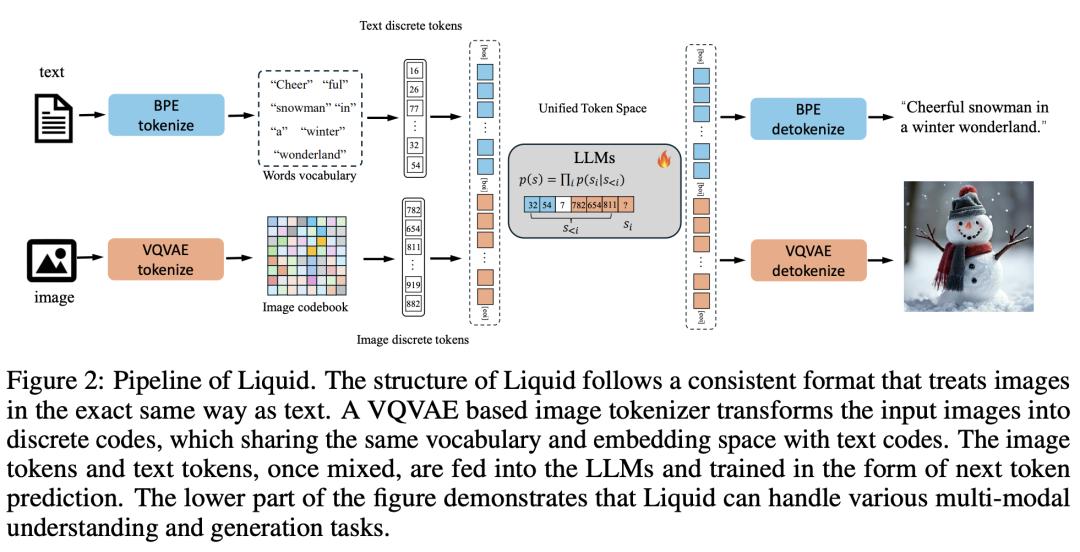
首次发现了一个 law,即随着模型规模的增大,视觉和语言任务的统一训练不可避免地会带来性能下降。统一的 token 空间还能使视觉生成和理解任务相互促进,有效消除早期模型中的干扰。
研究表明,现有的 LLM 可以作为 的基座,在多模态能力上好于 的还能节省 100 倍的训练成本,并保持与主流 LLM(如 )相当的语言性能。 在视觉语言和纯文本任务中的表现也优于 SD v2.1 和 SD-XL(在 MJHQ-30K 上的 FID 为 5.47)。
论文链接:
整理:学术君
如需转载或投稿,请直接在公众号内留言