
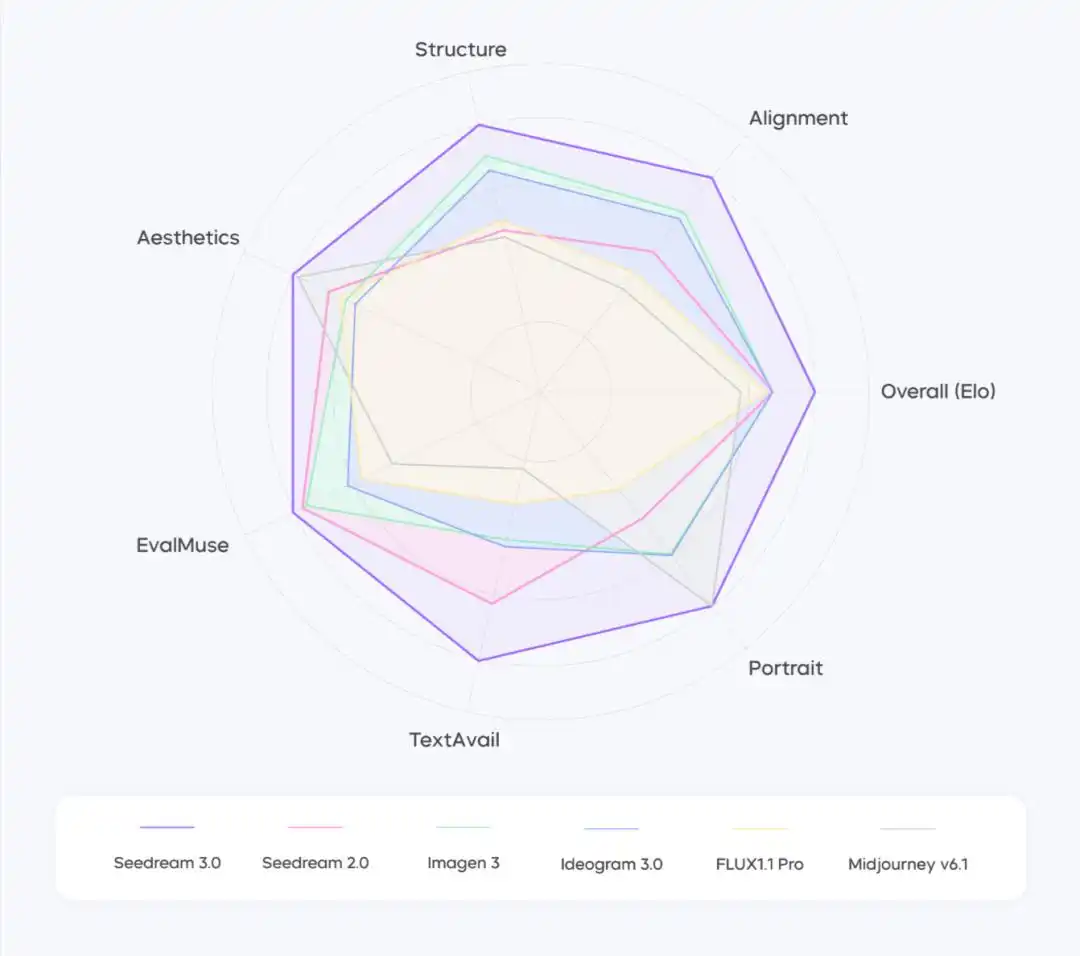
字节的“野心”,藏不住了

2025年春天,AI行业的一系列动作释放出一种不同以往的信号。GPT-4o以更强的多模态处理能力强化人机交互; R2持续推进开源攻势,刷新国产模型的技术期待;而字节跳动旗下的火山引擎,在杭州举行了一场没有太多华丽词藻但含金量颇高的发布会,核心关键词只有三个:深度思考、多模态推理、全栈Agent。
AI模型从“语言输出者”走向“任务执行者”,从生成文字、图像,到开始操作浏览器、编辑视频、理解图表乃至“看图做决策”。这并非简单的模型功能更新,而是AI能力边界的一次实质性拓展。在这场变化中,字节推出的豆包1.模型、.0文生图引擎、OS Agent平台化方案,构成了一个系统性的技术组合,也预示着其未来在AI生态中的角色将不再只是“提供一个大模型”。
但问题也随之而来:
推理能力和多模态能力,真的从实验室走向了可落地的规模化吗?
Agent的门槛是否已经抬升?开发者与企业会为这种能力买单吗?
在国产模型陷入“开源焦虑”时,字节为何依旧坚持平台化和自研路线?
火山引擎强调的“AI云原生”到底是,还是产业基础设施的重构?
这些问题不仅关乎一场发布会的技术意义,也反映了整个行业迈入“AI中场阶段”时的分歧与选择。在下文中,我们将从模型能力、视觉生成、Agent架构、云原生推理体系等多个层面拆解这次发布背后的深层结构,试图理解字节在做什么,又预判它意图成为谁。
豆包1.模型的真正突破
不只是参数或分数
豆包1.模型,是此次发布会中最具技术象征意义的一环。火山引擎称其为“具备多模态推理能力的通用大模型”,并公开对标 o3-mini-high、o1等模型。从测评数据上看,这款模型在多个专业推理任务中的表现确实可圈可点:
·在AIME 2024数学测试中,得分追平 o3-mini-high;
·编程挑战的pass@8分数接近 o1;
·GPQA科学推理成绩也已进入国际第一梯队;
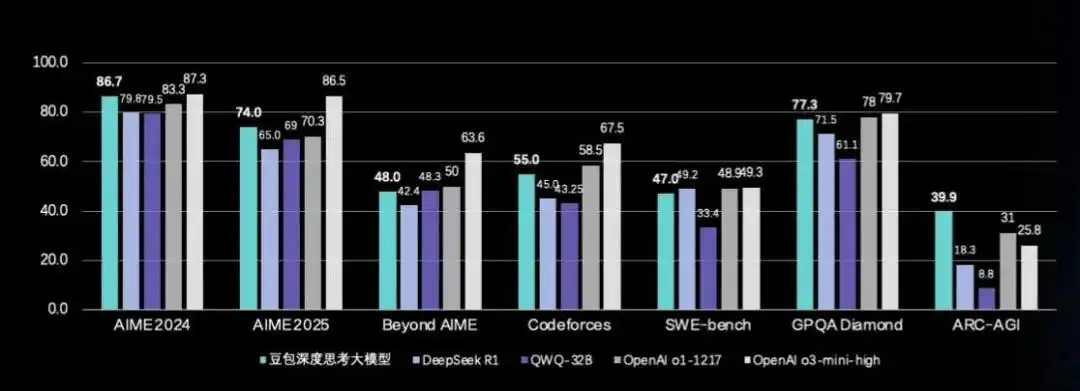
在通用任务上,豆包1.模型也展现了良好的泛化能力,涵盖人文问答、创意写作等更“主观”或具多义性的场景。
但这些分数背后,真正值得拆解的并不是模型在某一项榜单上的亮眼成绩,而是它所展现出的两类关键变化:一种是对“能力结构”的重组,另一种是对“推理成本”的系统性优化。
1. 推理结构重组:从对错判断到策略生成
豆包1.,采用的是 of (MoE)架构——这在如今的大模型圈已不算新鲜。但其配置策略值得注意:200B总参数规模中,仅激活20B。这意味着每次推理只动用模型中10%的能力单元,以此换取低能耗和高速响应。这种配置既是出于现实的算力调优考虑,也映射出火山引擎对“高并发、低延迟”场景的战略定位。
更关键的是其提出的“深度思考能力”,不仅是一个泛泛的修辞,而是包含推理链构建、策略评估、过程反思等底层机制。模型不仅能得出数学题的正确答案,还能解释其步骤;不仅识别航拍图中的地貌,还能判断开发可行性。这种“思·说·行”能力三段式的形成,才是真正将模型从语言处理者推向任务代理者的标志。
不过,在没有看到开源权重或详细的推理链报告前,这种能力仍需更多现实场景的检验。
2. 推理成本与API响应优化——模型服务的“工业化阶段”
火山引擎在此次发布中格外强调延迟与吞吐:“基于高效算法和高性能推理系统,API延迟最低可达20ms,支持高并发请求。”
这句话背后,其实藏着一个模型落地最大的问题:推理服务成本如何控制?
豆包1.的MoE架构,配合火山自研的推理框架,使得每次调用的计算资源消耗大幅降低。在内部估算中,GPU使用成本下降了80%。这一指标在云服务厂商中并不常见,却恰恰是“通用大模型想要规模化接入”的关键门槛。
推理延迟、资源复用、硬件适配(尤其是异构GPU)这些词,过去可能出现在高性能计算领域,如今却已成为大模型服务厂商必须精通的“下沉技术栈”。而火山引擎显然希望借此在 AI 服务层占据技术高地——不仅是模型做得好,更是模型“跑得快、跑得稳、跑得省”。
.0:
图像生成的“工业级”能力,真的来了?
在大模型快速发展的进程中,图像生成一度被视作最容易出圈的能力,但也因此最容易沦为“视觉炫技”。从 的开源风潮,到、DALL·E系列的不断迭代,视觉大模型早已不是新鲜事。但在这些“好看图”的背后,真正将图像生成能力“产业化”的问题,始终悬而未决:生成速度是否够快?生成内容是否可靠?能不能精准服务具体场景?模型指令是否能完全遵循?
在火山引擎这次发布的.0 中,这些问题得到了正面回应。
1. 从“会画画”到“画得准”:技术指标正逼近商业需求线
与前代相比,.0最大的特征是“结构可控性”和“商业适用性”的同步进化:
·支持2K分辨率图像直出,适配从手机屏到海报大屏的多场景应用;
·在图像结构、文本排版、小字生成、对象属性一致性方面,优于上一代模型;
·经实测,1K图像3秒出图,实现接近实时的响应速度。
从数据角度看,它不再只是一个“有灵气的AI画家”,而更像是一个“遵守设计稿规则的AI美工”,可以精确完成带约束条件的生成任务。
这在诸如电商详情页、商业海报、多语言社媒内容等领域,是一项极具价值的能力。
而它在 文生图竞技场中跻身第一梯队,也印证了模型的核心能力已进入全球竞品对抗的有效区间。
2. 美感之外,.0更强调的是“结构秩序”
目前市场上已有大量文生图工具,但大部分生成模型仍然对“结构”掌控力较弱,常见问题包括:
·文本与图像错位(尤其多语言下);
·多物体位置关系混乱;
·小字、复杂排版易模糊甚至乱码;
·指令遵循弱:描述有了,图像没有精准还原;
.0对此进行了针对性优化,其训练中引入了多分辨率混合策略,并强调“结构优先+ 语义还原”的机制。
这意味着,它不仅能“画”出让人惊艳的画面,更能在复杂的指令场景下严格执行格式、内容、语义的约束。
简言之,它更像一个“具备图文执行能力的模型接口”,而不是单一的创作工具。
这也是它区别于、 3这类更偏“艺术生成型模型”的地方——更工程化,更工具化。
3. 生成式图像的下一步:不只是好图,而是“可控的视觉接口”
随着生成模型与多模态交互的深度结合,图像不再只是“输出物”,而开始变成“指令输入”的一部分。例如:
·企业客户上传一张工厂俯视图,让模型识别危险区域;
·用户在图中圈出某个产品,模型自动生成对比图或改进图;
·用户描述“做一张包含蓝色主调、适合母婴产品的双语宣传图”,能输出结构良好的可商用图像;
这类场景的共同点是:图像的生成不再是孤立动作,而是被嵌入在一个更长链路的任务中。
在这种语境下,图像生成模型的竞争力,也从“图好不好看”,转向“图能不能用、能不能改、能不能嵌入上下文”。
.0释放出一个信号:图像生成模型的下一阶段,是从“创意产品”向“接口化视觉能力”过渡。它必须适应系统调用、结构控制和指令对齐的需求,而不是只服务于设计师的灵感时刻。
总结来说,.0在结构控制、分辨率输出、排版准确性等方面的突破,标志着图像生成模型第一次真正具备了“工程可用性”。它不是用来取代设计师的,而是让模型参与设计“前80%”的繁杂重复工作,帮助人类更快进入创意和决策层。
但也正因为此,的竞争对手不再是,而是“中的AI插件”、“Figma的协同助手”、“企业级自动设计引擎”。它必须证明自己不仅能画得好,更能画得对、画得快、画得进系统。
OS Agent:
工具,还是平台级基础设施?
如果说大模型解决了“理解世界”的问题,那么Agent的出现,试图解答“如何行动”。
但真正的挑战并不在于模型能否完成一个任务,而在于它能否持续完成链式任务、感知上下文并具备自主决策能力。
火山引擎此次推出的OS Agent,被描述为“面向企业的全栈Agent解决方案”,它不仅支持模型调用浏览器、电脑、云手机,还整合了视觉理解、界面定位和任务执行能力。从功能列表上看,它并不缺乏“炫技”的内容;但更值得关注的,是它试图搭建一套标准化Agent执行框架,从模型能力延伸到操作系统级别的交互控制。
1. Agent从“插件”到“操作系统”,OS Agent定位在哪?
过去一年,Agent成为行业热点,但大多数仍停留在“插件级”开发阶段:它们能做打卡签到、报销流程等任务,但依赖预设规则,缺乏泛化能力;它们能调用模型输出结果,但无法对执行环境(浏览器、桌面应用、移动端)实现统一理解和控制;它们的“多模态”更多是输入上的,而非“感知·推理·执行”的闭环。
而OS Agent试图解决的问题,本质是让模型“看得懂界面 + 操作得了界面”。具体包括两个关键模块:
·UI-TARS模型:这是此次发布中最有技术含量的部分,它融合了屏幕视觉理解、界面元素识别、操作逻辑推理三大能力;
·函数服务 + 云手机/云服务器:将传统浏览器、App等系统资源抽象成可调用接口,实现数字世界中Agent的“远程手脚”;
这种架构尝试不再以“开发任务脚本”来驱动Agent,而是以“模型自主探索 + 调度底层资源”来驱动。
说得更直白一点:OS Agent 就是试图成为Agent世界的“iOS + API Store”
2. MCP协议的提出:Agent也需要“互联网的HTML+HTTP”
在这次发布会上,火山引擎多次提到已支持MCP协议,可以看到,它正是为了统一Agent在不同系统中的交互接口和执行指令集。
这一动作类似于早期Web发展中HTML和HTTP协议的诞生:只有基础交互标准统一,Agent生态才能繁荣发展。
今天,各家模型厂商都在构建各自的Agent系统,但几乎都存在以下问题:接口各异,开发成本高;无法跨平台复用(移动端 vs 桌面端 vs 浏览器);缺乏统一的感知·控制语义协议(没有类似HTML的“按钮”、“输入框”、“导航栏”抽象)。
MCP的出现,意图打破这种碎片化:让模型调用系统的方式,像Web调用页面一样统一。
火山引擎的定位也很清晰:它不抢占“Agent内容创作者”的位置,而是希望成为那个构建“Agent生态操作系统”的云平台。
3. 模型调用正在进入“任务链时代”
目前,OS Agent展现了一个新的趋势:模型调用的单次问答已不再重要,任务链才是新的评估单位。
以发布会中演示的一个典型任务为例:用户输入“帮我找出 15在不同电商平台的最低价”,Agent调用浏览器 → 搜索商品 → 比较价格 → 汇总结果 → 生成推荐。
在这个过程中,大模型不是“回答一个问题”,而是在 主动发起子任务 + 识别界面结构 + 控制行为路径,并在多个模态中跳转。这种链式结构下的Agent,需要具备:多轮状态记忆与规划能力;视觉感知与环境理解;异常恢复与任务中断处理机制。
也就是说,OS Agent并不是一个应用,而是一种操作方式。
当然,尽管OS Agent展示出令人期待的方向性设计,但从系统Demo走向产业级部署,仍面临几个现实挑战:
1. 环境抽象的复杂度:当前不同系统的UI框架、控件形态差异巨大,实现统一理解仍需大量微调;
2. 安全与权限控制问题:让模型远程操控桌面、浏览器、手机,意味着必须有清晰的沙箱机制与权限边界;
3. Agent能力评估缺失:目前尚无标准化指标判断一个Agent“是否靠谱”,这在企业部署中尤其关键;
从火山引擎的策略看,它并不试图“一口吃成全栈AI系统”,而是从协议、平台、组件三个层面逐步释放能力,让开发者基于其构建Agent生态,这是一种更贴近基础设施厂商的节奏感。
是一个工具
还是一条护城河?
过去十年,云计算的故事一直围绕“弹性、稳定、安全”这几个关键词展开。AWS、Azure 和阿里云讲的是计算资源的高效调度、数据库的性能优化、微服务的治理能力。那时候,“云原生”意味着容器化、、CI/CD。
但进入AI 时代,这套范式正在快速失效。因为大模型不是服务的容器,而是吞吐量极高、延迟敏感的“算法体”。它们不仅要求“部署”,更要求“推理效率”;不仅要稳定运行,还要高频响应。
这正是“AI云原生”所要解决的问题。而火山引擎,显然把它作为区别于其他云厂商的战略核心。
1. :从推理能力到产品能力的转译器
在发布会中,火山引擎强调了一个相对陌生但非常关键的技术组件:。
这不是一个通用概念,而是火山引擎自研的推理服务系统,用于提升模型的部署效率、调用吞吐量、资源利用率。
根据数据猿获取的信息,主要解决以下几个层面的问题:
·高并发下的推理资源调度:支持异构硬件,自动分配计算资源;
·低延迟响应的优化机制:在PD分离(/)、KV Cache(Key·Value缓存)等底层模块上做了定制化;
·推理成本显著下降:GPU使用效率大幅提升,推理成本相比传统方案降低了 80%。
这些能力不仅服务豆包自身,更可以对第三方模型如、GLM等提供统一推理能力。也就是说,是火山引擎希望被“标准化输出”的产品能力,而非只在内部消化的技术资产。
2. 推理 ≠ 微服务:大模型运行机制对云提出新要求
传统云原生的核心目标是:快速部署+ 弹性扩缩 + 高可用冗余。
而AI 模型带来的新挑战在于:每次调用的计算量远大于传统API;响应延迟直接影响用户体验(特别是在多轮交互与链式调用场景);硬件资源(尤其是GPU)成为瓶颈,而不是廉价的通用CPU。
这意味着,大模型时代的云,不仅要像AWS提供函数一样“即用即弃”,更要提供推理服务的低成本、高密度、高可靠性调度系统。换句话说:模型是“核心燃料”,而推理系统才是“发动机”。
火山引擎正试图把这套推理发动机,从“模型专属配件”变成“所有AI应用的标配底盘”。
3. AI云原生 ≠ :它是一种新型系统能力组织方式
“AI 云原生”一词正在变得流行,但火山引擎给出了一个更具体、系统化的定义。它不仅包含模型部署与推理,还包括如下几个关键能力层:
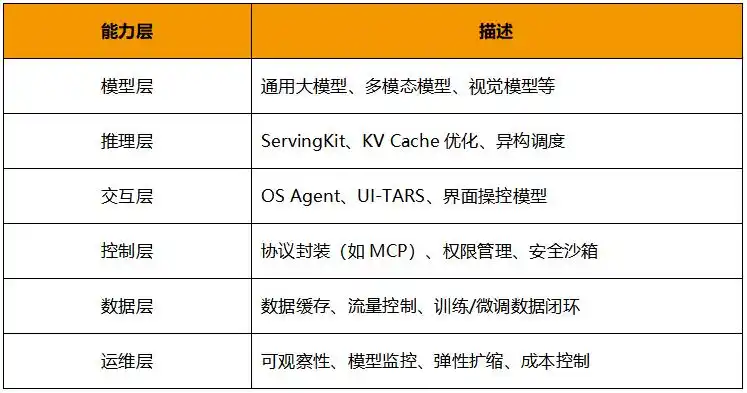
这种分层不是简单罗列组件,而是指向一个核心问题:如何让一个AI应用像做网站一样简单?
火山引擎的战略是,打造一个能复用、能组合、能服务所有Agent开发者与企业模型化需求的“AI原生操作环境”,不仅支撑豆包,也支撑未来的“千豆万包”。
火山引擎到底要成为什么?
在所有大模型公司里,字节跳动(火山引擎)是一个结构极为复杂的存在。一方面,它拥有面向C端的“豆包”应用,提供即时问答、多模态交互、图像生成等能力;另一方面,它又是一个ToB的云服务平台,推出包括、OS Agent、AI云原生套件在内的一整套“模型运行时基础设施”。
这套“双轨并行”的路线,比起专注做产品的、做平台的AWS,也许更像是一个“变形的苹果”:既造设备,也造系统,还提供服务。而问题在于,这种产品/平台并行模式,如何避免左右互搏?又如何形成协同效应?
要捋清这其中的关系,我们就需要搞清楚下面几个问题:
1. 豆包是验证能力的产品形态,而不是商业核心
从豆包的定位可以看出,它更像是火山引擎用来“验证大模型能力”的前台容器。在C端,它承担着如下几项职能:快速试错和收集反馈,推动模型能力微调与升级;落地用户场景,如问答、视觉输入、图像生成、文档分析等;作为示范案例,为企业用户提供可感知的“能力样本”。
但在实际商业逻辑中,豆包并非平台级收入来源——它更像一个产品原型孵化器,服务于整个模型平台的研发循环。
正如谭待所言:“今天你给它打100分,一个月后可能只剩60分。我们不是靠打分赢,而是靠迭代快、落地准。”在这种思维下,豆包不是终点,而是模型能力成长的压强器。

图:火山引擎总裁谭待
2. 平台化的底层逻辑:服务一切,不排斥任何模型
在平台维度,火山引擎则更明确地释放出开放信号:无论是自家模型(豆包)、开源模型()、还是行业合作模型(GLM、Kimi),都可以通过火山的云原生架构实现高效推理、低延迟部署和系统对接。
这背后有两个考量:
·技术层:推理系统的成本与效率,是所有模型(不论闭源开源)都必须面对的问题。火山引擎把自己定位成“性能放大器”;
·商业层:平台化模型托管可以扩大云服务市场份额,规避单一模型商业化路径的瓶颈与风险;
豆包可以是“优等生”,但火山不会因为它而排斥其他模型;甚至在多个公开场合,火山引擎表示对的适配速度是“市场最快”,接入数量也“遥遥领先”。这是一个典型的平台视角,而非产品护城河思维。
3. 火山策略的核心是“工具化”而非“体验闭环”
这与的路线形成鲜明对比。的GPT生态强调产品体验闭环:、GPT Store、Voice Mode、插件系统、个人化助手……试图把用户牢牢锁定在一个高度封闭、能力整合的超级App中。
而火山引擎强调的是“组件化工具链”:你可以用豆包,也可以不用;你可以用自己的模型,但推理调度交给我们;你可以开发自己的Agent,但在我们平台上更省钱、更快跑;
这使得火山引擎与其说是字节跳动的“大模型品牌”,不如说是一个“AI工程工具箱”平台。豆包、、OS Agent,都是这个工具箱里的预装模块,但不是唯一选项。
4. 多重身份的权衡术:火山如何在“大模型赛道”与“云基础设施”之间平衡?
当前,大模型企业大多在“自研闭环”与“平台生态”之间摇摆。火山引擎显然试图两者兼顾,但这种策略能否成立,取决于它能否解决以下三重身份间的张力:
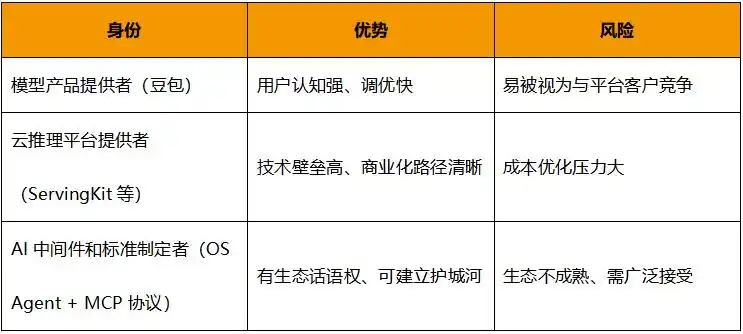
当前来看,火山的做法是“内外统一”——内部产品与外部服务采用相同的技术路径和工具链,强调技术复用、生态中立。
豆包是门面,云原生才是根基;模型是手段,平台才是目标。
火山引擎的定位,不是一家单纯的模型公司,也不是传统意义上的云厂商。它更像是在构建一个“面向模型生态的开发与运行基础设施平台”。豆包是一面镜子,照出的是火山能否做好平台的能力,而不是火山的全部。
综上,人工智能技术发展至今,已走过了以“语言生成”为代表的上半场。模型的对话能力、文本创作、信息总结、通识问答——这一阶段的突破足够惊艳,也促成了公众对AI的广泛关注。
但进入2025年,行业面临的难题已不再是“说得好不好”,而是“干得行不行”。从多模态感知到复杂任务执行,从结构化输出到系统化联动,AI正逐步从“表达能力”走向“执行能力”。
这意味着,大模型竞争的重心已经移位:模型本体不再是唯一的核心资产,模型能力的“运行方式”、推理系统的“调度效率”,才是决定其产业落地速度的变量。
而构建这些变量的,不是单一模型实验室,而是成体系的AI基础设施提供者。这不是一场短跑,而是一次基础设施战役。谁能真正把模型“跑起来”“用得起”“接得上”,谁就拥有了AI时代的通用调度权。
如果说过去的AI是“一个人会说话”,那么未来的AI是“一个系统能办事”。谁能构建那个能办事、愿被信任、运行高效的系统,谁就能赢得下一个十年的AI底座之战。
文:一蓑烟雨/ 数据猿