
o3模型基准测试分数仅为10%,远低于OpenAI宣传的25%

这并不意味着 在说谎!
站长之家() 4月21日 消息: 的新 AI 模型 o3 在首先方和第三方基准测试结果上存在差异,这也引发了人们对该公司透明度和模型测试实践的质疑。去年 12 月, 的 o3 模型初次亮相,当时,该公司宣称这款模型能够解答 (一组相当挑战性的数学问题)中超过 25% 的题目 —— 这个成绩远超竞争对手 —— 第二名的正确率约为 2%。
“目前,市面上所有AI产品在 上的得分都低于 2%,” 首席研究官马克・陈(Mark Chen)在一次直播中表示,“我们(在内部测试中)发现,在激进的测试计算条件下,o3 能够达到超过 25% 的正确率。”
但事实证明,这个数字很可能是上限,实现这一成绩的 o3 版本所使用的计算资源比 上周公开推出的模型得多得多。
上周五, 所属研究机构 Epoch AI 公布了针对 o3 的独立基准测试结果。他们发现,o3 的得分约为 10% —— 远低于 所宣称的 25%。
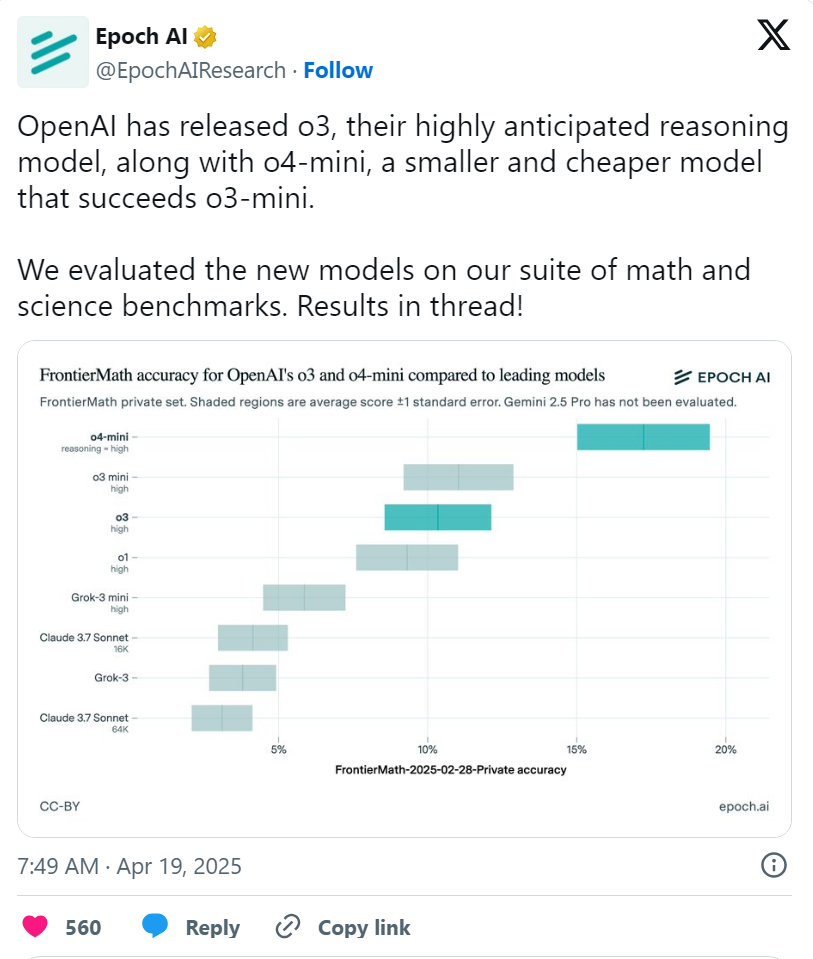
当然,这并不意味着 在说谎 —— 在去年 12 月公布的基准测试结果还游一个“下限得分”,这个“下限”与 Epoch 观察到的得分相符。Epoch 还指出,其测试设置可能与 的不同,并且在评估中使用了更新版的 。
Epoch 写道:“我们的结果与 的结果存在差异,可能是因为 使用了更强大的内部架构进行评估,在测试时使用了更多计算资源,或者是因为这些结果是在 的不同子集上运行得出的( - 2024 - 11 - 26 中的 180 道题与 - 2025 - 02 - 28 - 中的 290 道题)。”
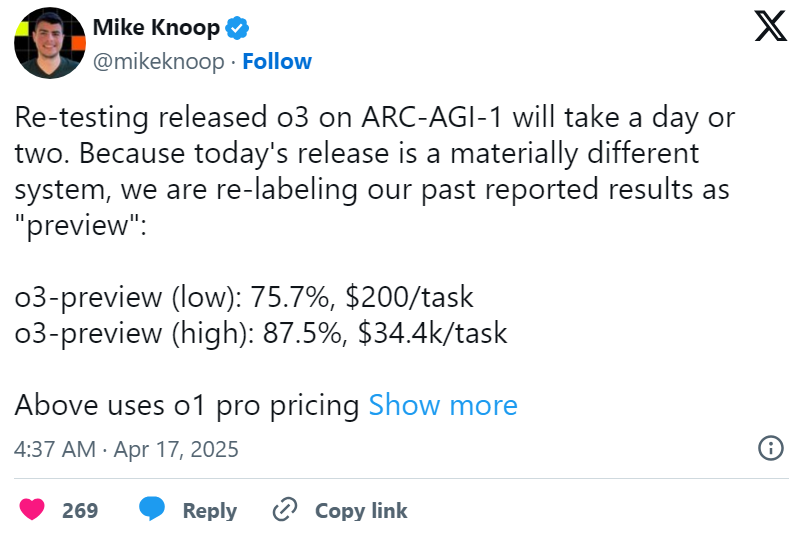
曾测试过 o3 预览版的 ARC Prize 在 X 上发帖称,公开的 o3 模型 “是另一个为聊天 / 产品使用场景进行调优的模型”,这证实了 Epoch 的报告。ARC Prize 写道:“所有已发布的 o3 计算层级都比我们(做基准测试时使用的)版本要小。” 一般来说,计算层级越高,基准测试得分可能越好。
上周, 的技术人员 Wenda Zhou 在一次直播中表示,与 12 月展示的 o3 版本相比,投入实际应用的 o3 “针对现实应用场景和速度进行了更多优化”。他补充说,因此可能会出现基准测试 “差异”。“我们进行了(优化),让(模型)更具成本效益,总体上更有用,” Zhou 说,“我们仍然希望 —— 也依旧认为 —— 这是一个更好的模型…… 当你提问时,不需要那么久的等待时间,对于这类模型来说,这很重要。”
这再次提醒人们,对于 AI 基准测试结果,较好不要轻信表面数据 —— 尤其是当数据来源是一家要推销服务的公司时。